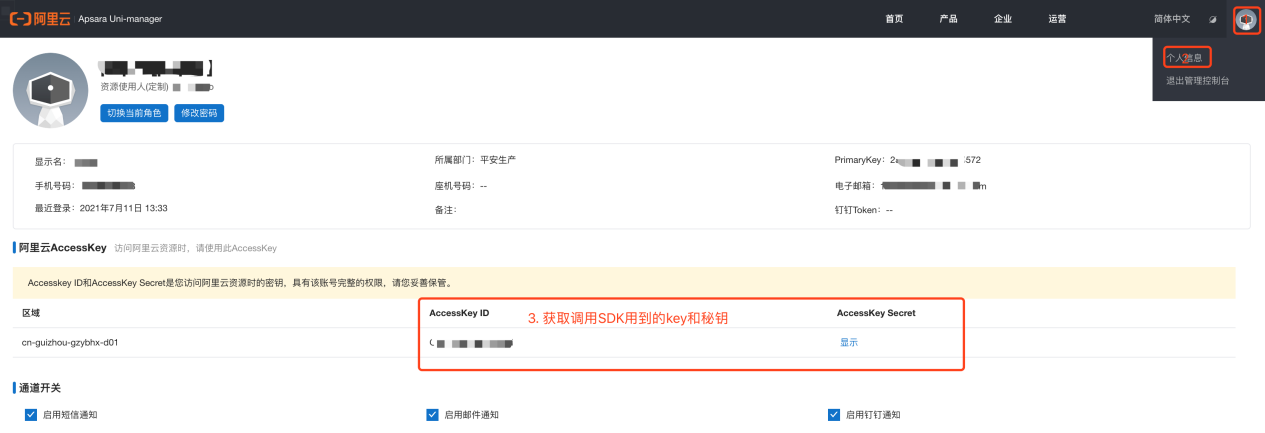
获取调用SDK授权账号
- 1.用户账号登陆阿里云平台网址
- 2.按照如下步骤获取对应的授权账号 key和秘钥
- 3.获取项目名称和endpoint
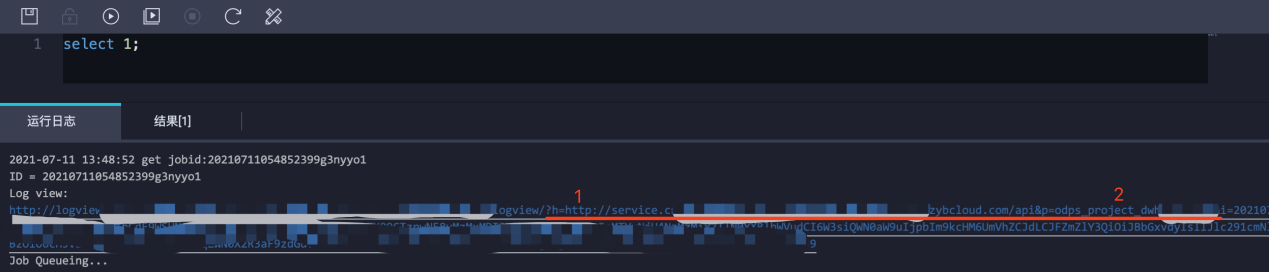
如下图所示, 随意新建一个临时查询,点击执行后查看日志中的log view
- 参数h=xxxx (xxxx 即为endpoint)
- 参数p=yyyy (yyyy 即为项目名称)
调用SDK访问数据中台访问表
- 1.新增一个maven项目
mvn archetype:generate \
-DgroupId=cn.pingan \
-DartifactId=test_odps \
-DarchetypeArtifactId=maven-archetype-quickstart \
-DarchetypeCatalog=local \
-DinteractiveMode=false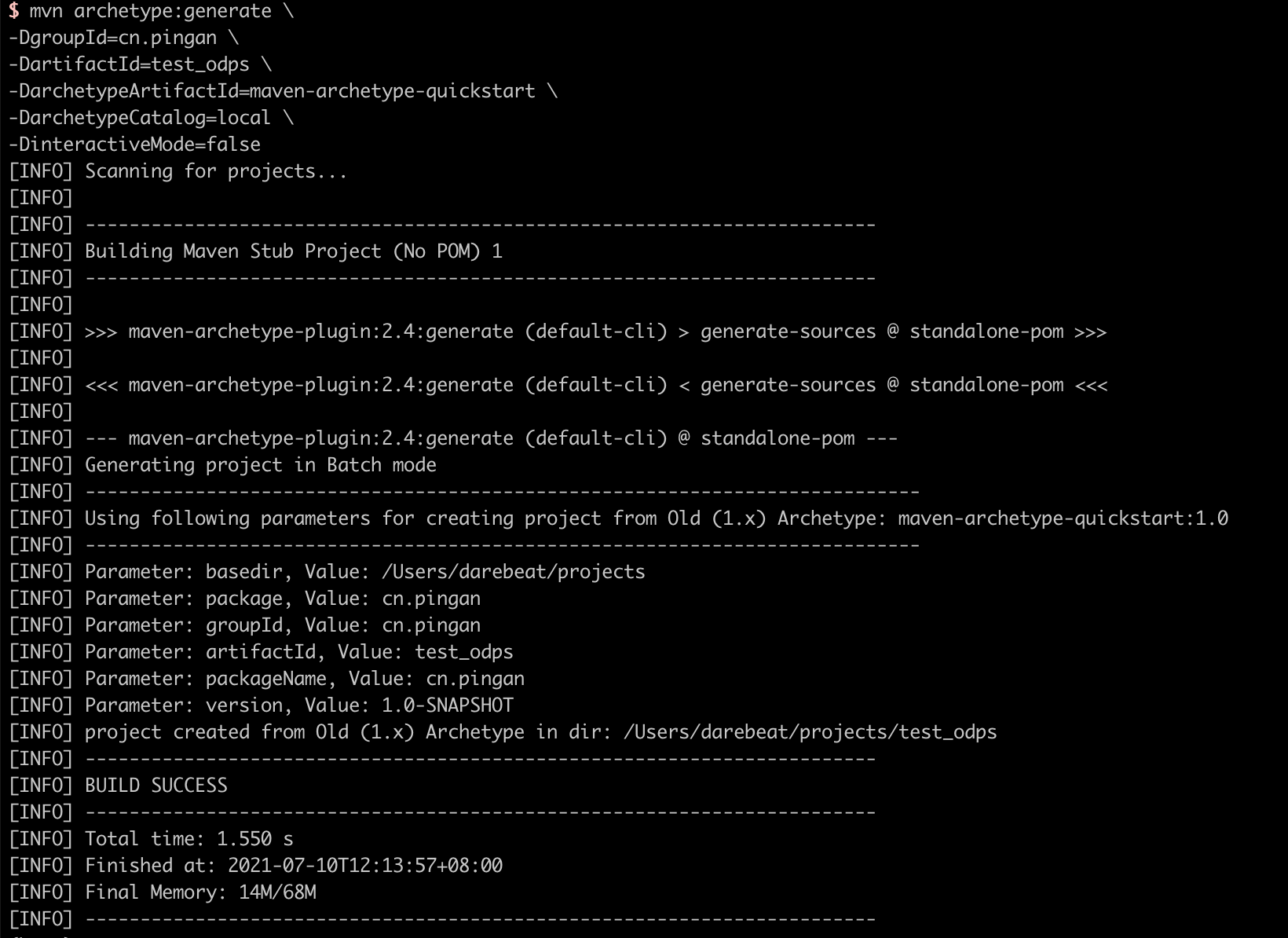
- 2.根据需要在 pom.xml 中添加依赖包
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-sdk-core</artifactId>
<version>0.37.9-public</version>
</dependency>
<!--<dependency>-->
<!--<groupId>com.aliyun.odps</groupId>-->
<!--<artifactId>odps-sdk-commons</artifactId>-->
<!--<version>0.37.9-public</version>-->
<!--</dependency>-->
<!--<dependency>-->
<!--<groupId>com.aliyun.odps</groupId>-->
<!--<artifactId>odps-sdk-udf</artifactId>-->
<!--<version>0.37.9-public</version>-->
<!--</dependency>-->
<!--<dependency>-->
<!--<groupId>com.aliyun.odps</groupId>-->
<!--<artifactId>odps-sdk-mapred</artifactId>-->
<!--<version>0.37.9-public</version>-->
<!--</dependency>-->
<!--<dependency>-->
<!--<groupId>com.aliyun.odps</groupId>-->
<!--<artifactId>odps-sdk-graph</artifactId>-->
<!--<version>0.37.9-public</version>-->
<!--</dependency>-->- 3.小于10000条记录数据读取
tasksql通过sql查询,对记录数有10000条的限制
import com.aliyun.odps.Instance;
import com.aliyun.odps.Odps;
import com.aliyun.odps.OdpsException;
import com.aliyun.odps.account.Account;
import com.aliyun.odps.account.AliyunAccount;
import com.aliyun.odps.data.Record;
import com.aliyun.odps.task.SQLTask;
import java.util.List;
public class TaskSql {
private static final String accessId = "<your key>";
private static final String accessKey = "<your secret>";
private static final String endPoint = "";
private static final String project = "";
private static final String sql = "select 1 id,'test' as name union all select 2 id,'tasksql' as name;";
public static void main(String[] args) {
Account account = new AliyunAccount(accessId, accessKey);
Odps odps = new Odps(account);
odps.setEndpoint(endPoint);
odps.setDefaultProject(project);
Instance i;
try {
i = SQLTask.run(odps, sql);
i.waitForSuccess();
List<Record> records = SQLTask.getResult(i);
for(Record r:records){
System.out.println(
r.get(0).toString()+","+
r.get(1).toString()+","+
r.getString("name")
);
}
} catch (OdpsException e) {
e.printStackTrace();
}
}
}4.配合Tunnel,解决大批量数据导出
import com.aliyun.odps.Instance;
import com.aliyun.odps.Odps;
import com.aliyun.odps.OdpsException;
import com.aliyun.odps.TableSchema;
import com.aliyun.odps.account.Account;
import com.aliyun.odps.account.AliyunAccount;
import com.aliyun.odps.data.Record;
import com.aliyun.odps.data.RecordReader;
import com.aliyun.odps.task.SQLTask;
import com.aliyun.odps.tunnel.TableTunnel;
import com.aliyun.odps.tunnel.TableTunnel.DownloadSession;
import com.aliyun.odps.tunnel.TunnelException;
import java.io.IOException;
import java.util.UUID;
/**
* Created by darebeat on 2021/7/11.
*/
public class TunnelSql {
private static final String accessId = "<your key>";
private static final String accessKey = "<your secret>";
private static final String endPoint = "";
private static final String project = "";
private static final String sql = "select '1' id,'test' as name union all select '2' id,'tasksql' as name;";
private static final String table = "t_export_" + UUID.randomUUID().toString().replace("-", "_");//此处使用随机字符串作为临时导出存放数据的表的名字。
private static final Odps odps = getOdps();
public static void main(String[] args) {
System.out.println(table);
runSql();
tunnel();
}
/*
* 下载SQLTask的结果。
* */
private static void tunnel() {
TableTunnel tunnel = new TableTunnel(odps);
try {
DownloadSession downloadSession = tunnel.createDownloadSession(project, table);
System.out.println("Session Status is : "+ downloadSession.getStatus().toString());
long count = downloadSession.getRecordCount();
System.out.println("RecordCount is: " + count);
RecordReader recordReader = downloadSession.openRecordReader(0, count);
Record record;
while ((record = recordReader.read()) != null) {
consumeRecord(record, downloadSession.getSchema());
}
recordReader.close();
} catch (TunnelException e) {
e.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
}
}
/*
* 保存这条数据。
* 如果数据量少,可以直接打印结果后拷贝。实际使用场景下也可以使用JAVA.IO写到本地文件,或在远端服务器上保存数据结果。
* */
private static void consumeRecord(Record record, TableSchema schema) {
// TODO do your custom data export operation
System.out.println(record.getString("id")+","+record.getString("name"));
}
/*
* 运行SQL ,把查询结果保存成临时表,方便后续用Tunnel下载。
* 保存数据的lifecycle此处设置为1天,如果删除步骤失败,也不会浪费过多存储空间。
* */
private static void runSql() {
Instance i;
StringBuilder sb = new StringBuilder("create table ").append(table)
.append(" lifecycle 1 as ").append(sql);
try {
System.out.println(sb.toString());
i = SQLTask.run(getOdps(), sb.toString());
i.waitForSuccess();
} catch (OdpsException e) {
e.printStackTrace();
}
}
/*
* 初始化MaxCompute的连接信息。
* */
private static Odps getOdps() {
Account account = new AliyunAccount(accessId, accessKey);
Odps odps = new Odps(account);
odps.setEndpoint(endPoint);
odps.setDefaultProject(project);
return odps;
}
}


